Migrating Swash from HBase to Redshift
This blog describes how Swash has migrated from it’s old data layer (HBase) to a new, cloud-based data layer (Redshift).


This blog describes how Swash has migrated from it’s old data layer (HBase) to a new, cloud-based data layer (Redshift).
Swash enables people to take ownership over their data by gaining control and receiving their share from the profits their data generates. It enables developers to innovate a new generation of data solutions, and businesses to access high-quality data without intermediaries.
To do this, Swash must therefore store a sizable amount of user data in a format that makes it possible to query, process, and retrieve the data quickly and efficiently.
It is clear that a convenient data lake can make all of these operations much easier. Initially, we chose HBase as our selected data lake, but have recently made the switch to Redshift. Keep reading for details on the migration.
Overall Data Flow
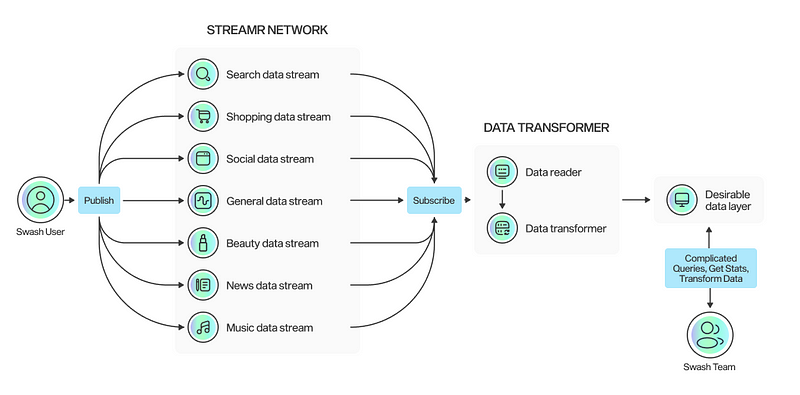
Swash users’ data is made available in data Streamr databases, which are where we can subscribe to and read the data from. However, we have no way of running complicated queries or analysing the existing data. So we use the Streamr client to read the daily data, transform it into the necessary format, and then insert it into our data lake.
With this solution, we are able to analyse the data, generate reports and statistics, and convert the data into a form useful to our customers before delivering it to them.
HBase as our data lake
Considering our criteria, we needed a scalable and efficient data lake to store the user data collected from those using Swash app. After significant investigation, we ultimately decided to proceed with HBase above all other SQL and No-SQL databases.
Scalability was the first factor that we took into consideration. As has been claimed, HBase is designed to handle scaling across thousands of servers and managing access to petabytes of data. With the elasticity of Amazon EC2, and the scalability of Amazon S3, HBase is able to handle online access to massive data sets.
The second element that was taken into account was latency. According to the documentation, HBase provides low latency random read and write access to petabytes of data by distributing requests from applications across a cluster of hosts. Each host has access to data in HDFS and S3, and serves read and write requests in milliseconds.
Finally, last but not the least, it was critical for us that the chosen database would easily be able to tolerate any failure. HBase splits data stored in tables across multiple hosts in the cluster and is built to withstand individual host failures. As data is stored on HDFS or S3, healthy hosts will automatically be chosen to host the data once served by the failed host, and data is brought online automatically.
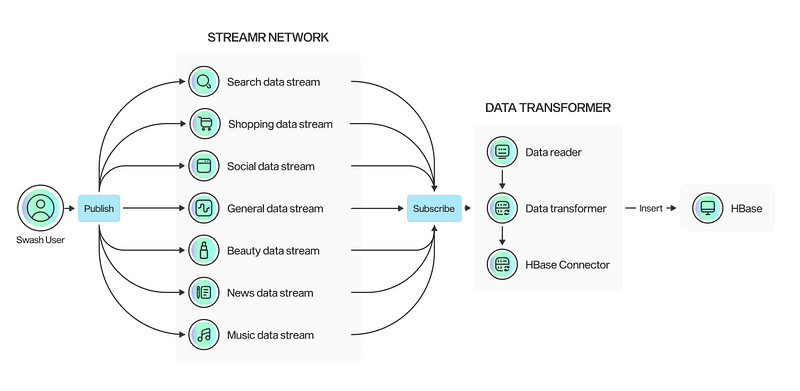
At first, HBase met our demands but, as time went on, a number of limitations showed up and HBase no longer met our needs. These limitations, which we will discuss in the following section, caused us to migrate to another data lake despite all the challenges involved.
Limitations when using HBase
In any production scenario where HBase is functioning with a cluster of numerous nodes, only one Hmaster server serves as the master to all the slave Region servers.
It will take some time to restore Hmaster if it crashes, even if the client can connect to the region server. It is possible to have more than one master, but only one will be active. Time is needed to activate the backup Hmaster if the primary Hmaster fails. In our case, Hmaster turned into a performance bottleneck, resulting in some downtime that could be avoided.
HBase does not provide cross-data operations or joining operations. Of course, MapReduce can be used to construct joining operations, but this would require much planning and development. In HBase, table join operations are challenging. In several of our scenarios, it was impractical to design join operations using HBase tables.
When we wanted to move data from RDBMS external sources to HBase servers, a new design for HBase was necessary. However, this procedure was time-consuming.
HBase is also quite difficult to query. It is possible that we link HBase with some SQL layers, such as Apache Phoenix, so that we can create queries that cause the data in HBase, but Phoenix’s buff was insufficient and it wasn’t fast enough to meet our standards.
Another issue with HBase is that it only allows for one indexing per table; the row key column serves as the primary key. Therefore, anytime we needed to query on more than one field or something other than the Row key, the performance was not up to par. Also, in terms of employing key values to search a table’s contents, key lookup and range lookup restricted real-time queries.
Only one default sort is supported by HBase per table, and partial keys are not fully supported. These two restrictions also presented us with some fresh challenges.
Finally, not only it was difficult to control user access to the HBase data, but also HBase was expensive in terms of memory block allocations and hardware requirements.
Due to the aforementioned constraints, we decided to migrate to another data lake that better fulfils our needs.
Proposed data layer
After much research and discussion, we ultimately decided on an ideal data lake that combines AWS S3 and Redshift. We keep the raw data in an S3 bucket, and insert transformed data into some Redshift tables in an effective and useful manner.
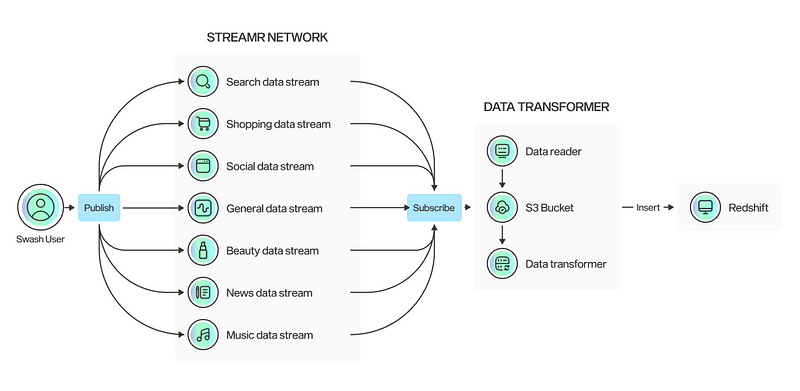
Storing raw data within an S3 Bucket
According to the concepts of usage, analytics, and cost, storing raw data inside S3 folders is the best course of action. When it comes to usage, using bucket permission policies gives us easier and more precise access control. Additionally, files are simpler to navigate without requiring a sophisticated environment configuration or technical expertise.
Regarding analytics, AWS offers a variety of compatible choices to load data into analytical warehouses. Additionally, an S3 path can be set to only load specific data from S3 to analytical warehouses.
Finally, storage on S3 is economical, and it has different cost levels based on the retrieval frequency.
It would be helpful to state that we took into account a few patterns when storing data in the S3 bucket. First, we proposed levels of storage hierarchy separated by types of data and date, hour and minute (YYYYMMDD/HHMM).
Secondly, within each folder, we also proposed to split the files into some equal parts to enable parallel loading into Redshift. Finally, the raw files should be stored in CSV with minimal-to-no transformation, and to further minimize storage all files should be in GZ format.
As an example, the data below refers to the Amazon Shopping file for the date 2022–9–12 09:30 saved as follows:

Selecting Redshift as the main warehouse
As previously mentioned, Redshift has been chosen as our primary warehouse as nobody can deny the fact that performance is the key consideration when looking for the best data warehouse.
Redshift uses “clusters” of data, which are collections of nodes, to organise its data. Each primary node is connected to a number of other nodes, and these nodes can operate concurrently to enhance quick data processing.
Although Redshift is fundamentally a beefed-up version of the PostgreSQL relational database management system (RDBMS) and uses technology from ParAccel - the first database to offer functional Massive Parallel Processing - this gives Redshift a significant performance advantage over older database technologies, like Postgres.
Redshift is constantly upgrading and improving since it makes use of machine learning capabilities to enhance performance and throughput. Redshift is not constrained by CPU or memory utilisation because it can also query data using serverless query compilation. Below, we briefly discuss some of the benefits of Redshift that persuaded us to choose it as our main warehouse.
First of all, Redshift - according to Amazon - processes data three times faster than rivals with similar prices. It’s also offered by Amazon at a sliding price range, making it affordable for smaller companies while still being powerful enough for large corporations working with data in many forms. Additionally, Redshift is a fully scalable data warehousing alternative for data integration because of the pricing’s extreme flexibility.
The amount of data that organisations use varies for a variety of reasons, including peak times, general demand, and uncontrollable external factors. Redshift is a desirable solution for enterprises of all sizes with full scalability because of how simple it is to remove or add nodes.
Furthermore, SQL command users will find the Redshift ecosystem to be very easy to utilise. Additionally, the AWS Management Console makes it simple for users to add, remove, or scale up or down Amazon Redshift clusters, making the Redshift data warehouse straightforward to understand.
Finally, Redshift is a cloud data warehouse that offers end-to-end encryption, network isolation, data masking, and a number of other capabilities to support companies in maintaining data security regardless of the types of data they utilise. For SQL queries, Redshift also supports SSL connections.
Designing the warehouse
After deciding on Redshift as Swash’s main warehouse, the next step was to effectively build the Redshift database structure. Some guidelines were taken into account when designing the data warehouse.
First, we tried to reduce the number of tables to enhance the analyst experience and provide the best possible querying and joining experiences. Then, the data content had to be self-explanatory in the table names. Finally, we made an effort to improve query and data storage performance.
Lookup tables should be used to store any columns that might not be frequently used or that might not appear in every row separately in order to do this. Our data has been divided into two types “Data” and “Meta Data.” When a piece of raw data is repetitive, like demographics information, it doesn’t need to be saved every time. This is called Meta Data.
These were the key factors taken into account when designing the Redshift database.
Conclusion
After switching from HBase to Redshift, we can now run our analytical queries on the data in a simple way, and performance has significantly increased. By creating meta data tables, we have lessened the amount of redundant information.
Due to Redshift’s cloud-based architecture, maintenance has been made much simpler and user management is now easier. There is almost no unpredictable downtime, and we have the potential to quickly scale the cluster with little to no downtime. Finally, a significant cost reduction has occurred.
About Swash
Know your worth and earn for being you, online.
Swash is an online earning portal where you can earn up to $200 per month for being active and completing tasks online. Whether you’re surfing the web, seeing ads, or sharing opinions, you deserve to be thanked for your efforts.
New ways to amp up your earnings are added to Swash every month!
Alongside the Swash earning dashboard, Swash consists of a wide network of interlinking collaborators including:
- brands that publish ads with Swash Ads
- businesses that buy and analyse data with sIntelligence
- data scientists who build models with sCompute
- developers who innovate on the Swash stack
- charities who receive your donations with Data for Good
Swash has completed a Data Protection Impact Assessment with the Information Commissioner’s Office in the UK and is an accredited member of the Data & Marketing Association.
Nothing herein should be viewed as legal, tax or financial advice and you are strongly advised to obtain independent legal, tax or financial advice prior to buying, holding or using digital assets, or using any financial or other services and products. There are significant risks associated with digital assets and dealing in such instruments can incur substantial risks, including the risk of financial loss. Digital assets are by their nature highly volatile and you should be aware that the risk of loss in trading, contributing, or holding digital assets can be substantial.
Reminder: Be aware of phishing sites and always make sure you are visiting the official https://swashapp.io website. Swash will never ask you for confidential information such as passwords, private keys, seed phrases, or secret codes. You should store this information privately and securely and report any suspicious activity.



