sCompute Architecture
With sCompute, Swash provides a way for data scientists to perform computations on the data without needing to purchase it. The data itself…


With sCompute, Swash provides a way for data scientists to perform computations on the data without needing to purchase it. The data itself remains private and is not sold or moved.
sCompute allows sClients, such as data scientists and sApps, to perform computations on raw Swash data on-premise and in a privacy-preserving manner. They do not need to purchase the data, instead they only pay fees related to the computation itself.
They can connect via the provided API or sPortal to deploy their algorithms. Computations can be fed by existing datasets or statistical data, or even the result of other computations. The results of the computation can then be stored as a dataset where it can be resold as a data product. The owner of the dataset and those whose data contributed to it will receive compensation when this is sold to data buyers. Computation results can also be made available only to the owner of the algorithm.
Despite the fact that created datasets have different identities for a user for different categories, in datasets created for computation, all identities of a user are mapped to a unique identity which correlates to all user data points collected through different collecting rules.
To preserve privacy, all algorithms should be audited manually before being used by the computation service to ensure that they are not trying to infer the identities of users and are aligned with Swash’s principles and standards for security. The Swash sCompute solution uses customised secure computation infrastructure to allow for trustless and autonomous interactions.
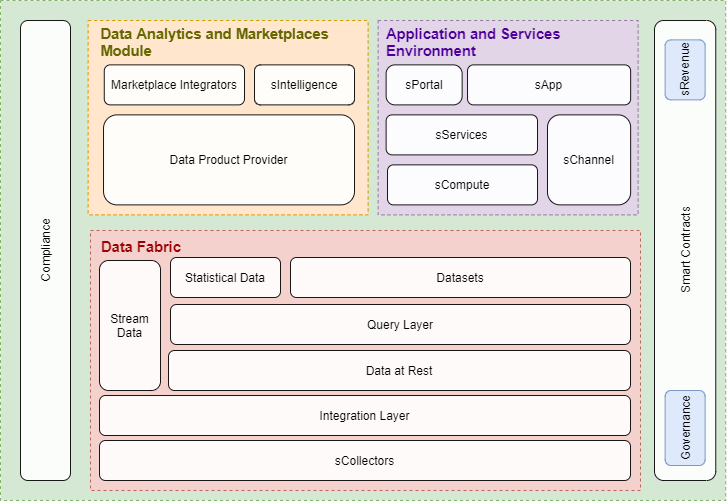
General architecture
You can see an overview of sCompute general architecture below. This image shows how the main components of this system communicate with each other to conduct computation based on predefined sCompute requirements.
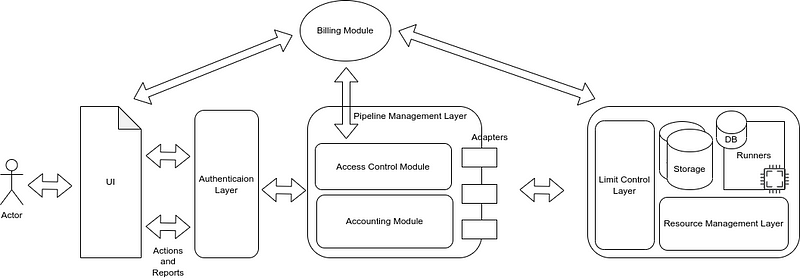
In the following section, the structure of these components will be described in more detail and their responsibilities will be explained.
Authentication layer
Registration, authorisation, authentication and session management are the most important services of this layer.
Registration flow
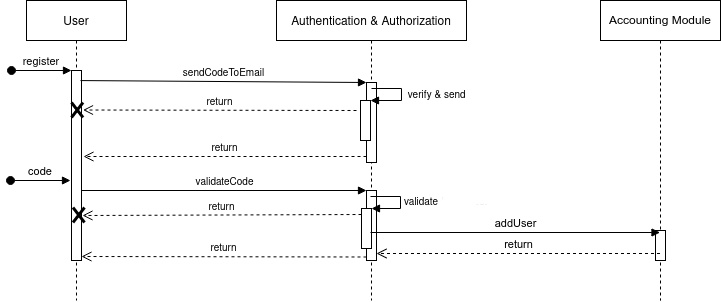
Registration operation uses an email verification approach that includes mailing a verification code to user to validate them. After this, the new user is added to the sCompute app.
Login flow
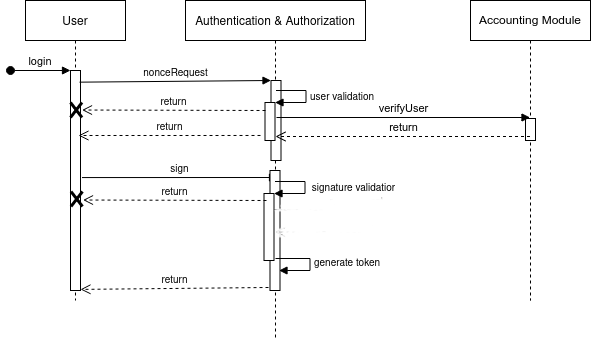
In this flow, the user is verified and authorised based on their wallet address and using a related private key. At the end of this flow, a secure token containing their identity information is generated and used to manage session management requests.
Session management
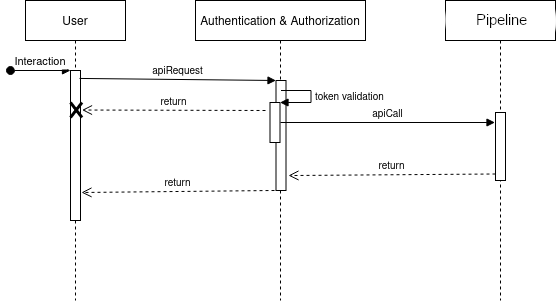
For each API call or interaction, an access token is put in requests. The authentication layer then validates each request and updates user activity. Now, once validated, requests can be completed and their results are returned.
Stateless interaction
The client’s valid Ethereum wallet could also be used for authentication. It means that a client’s unregistered wallet address could be used for authentication and interaction purposes. However, the signature generation method mentioned in the login flow is completed for each interaction.
Pipeline management layer
This is the main component of sCompute. As previously mentioned, sCompute allows sClients, such as data scientists and sApps, to perform computations on raw Swash data. The pipeline management layer is responsible for providing this capability by controlling access to data and accounting. Let’s start by taking a look at the pipeline concept.
Swash pipeline
sPipeline is a work flow of computation. This concept consists of a series of interconnected steps that are defined as follows.
- Pre-processing
- Training
- Evaluation
- Prediction
The structure of a pipeline is determined by the data dependencies between steps. These data dependencies are created when the properties of a step’s output are passed as the input to another step.
In sCompute, the sPipeline is defined and ready to be used as a computation stack.
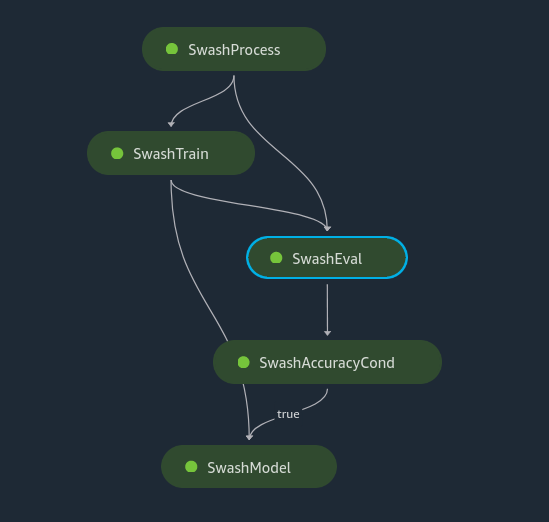
The pipeline management layer use access control and accounting modules to handle the pipeline flow.
Access control module
This module defines users’ activities based on their allocated resources. Running a pipeline requires some resources such as machines with CPU power for processing, and storage for saving results and log files. Therefore, the access control module communicates with the billing module and resource management layer to define user access based on dedicated resources to their own computation operation.
Accounting module
This module checks the user’s limitation and controls the user’s access based on these limitations. The accounting module should be able to answer a question about the current user:
- Did he pay for the required resources in current pipeline?
Running pipeline flow
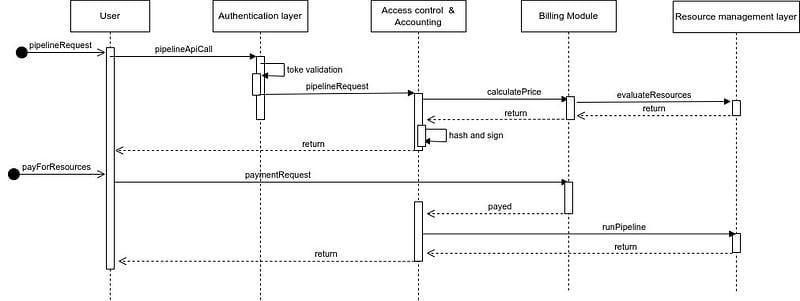
When a pipeline is requested, after the token validation in the authentication layer, the access control module checks the required resources for the pipeline in corporation with the accounting module.
Then the price of those required resources is calculated using the billing module and is based on resource evaluation of the resource management layer. If the payment is complete, the resources are allocated to the current pipeline and the execution can begin.
Resource management layer
As mentioned previously, dedicating resources to each pipeline and releasing them at the end is the most prominent responsibility of this layer. The resource management layer helps the pricing system to calculate the price of requested resources. Also, limiting usage and extending resources could be achievable via this layer.
Limit control layer
One of the biggest concerns in our system is controlling the output results. This layer helps us to apply some limitations over the output results. This layer is also responsible for filtering and sanitisation. For example, generating logs while the pipeline execution conducts other outputs. This layer controls the logs to prevent information leakage. Removing and replacing important information, such as IDs, paths, IPs etc, are included as part of this prevention action.
About Swash
At Swash, if it’s your data, it’s your income.
Swash is an ecosystem of tools and services that enable people, businesses, and developers to unlock the latent value of data by pooling, securely sharing, and monetising its value.
- People share their data to earn while retaining their privacy.
- Businesses access high-quality, zero-party data in a sustainable and compliant way.
- Developers set up and build systems within a collaborative development framework with ease.
As the world’s leading Data Union, Swash is reimagining data ownership by enabling all actors of the data economy to earn, access, build and collaborate in a liquid digital ecosystem for data.
Let’s connect:
Twitter | Telegram | Reddit | Discord | Website | All links
Swash has completed a Data Protection Impact Assessment with the Information Commissioner’s Office in the UK and is an accredited member of the Data & Marketing Association.
Nothing herein should be viewed as legal, tax or financial advice and you are strongly advised to obtain independent legal, tax or financial advice prior to buying, holding or using digital assets, or using any financial or other services and products. There are significant risks associated with digital assets and dealing in such instruments can incur substantial risks, including the risk of financial loss. Digital assets are by their nature highly volatile and you should be aware that the risk of loss in trading, contributing, or holding digital assets can be substantial.
Reminder: Be aware of phishing sites and always make sure you are visiting the official https://swashapp.io website. Swash will never ask you for confidential information such as passwords, private keys, seed phrases, or secret codes. You should store this information privately and securely and report any suspicious activity.



